网站大概是在78月建的,但是近期我才加入了网站统计数,之前的访问数全部归零,虽然没多少但总觉得有点可惜,就研究了一下如何修改这个访问量。其实是比较轻松的一件事。

这是截至我写文章的时候网站的访问量统计显示,其中99%是我刷的,昨天早一些的时候,这个数字只有200左右,还有大半是我自己的访问量(
我用的网站网站访问次数计数器是不蒜子,其实开始我是对着大佬的博客里的网站访问次数统计流口水想要又不知道怎么去搞,也就一直拖着没去做,直到有一天在看一篇PHP反序列化的文章底部再一次有看到了高贵的计数器,我决定做一些。由于大部分佬的博客底部的界面都出奇的相似,无外乎是长这样的

当时感觉为什么大部分的人用的都是同一个模板,感觉可能是某种公共服务,于是我直接去看源码,找到和计数有关的部分

感觉busuanzi比较可疑,用关键词找到相关js文件,进一步确定这是外包服务

当时脑子也不好使,以为是卜算子,去谷歌搜了之后被狠狠教育了。这是不蒜子的官方网站,里面其实已经把教程写的很清楚了
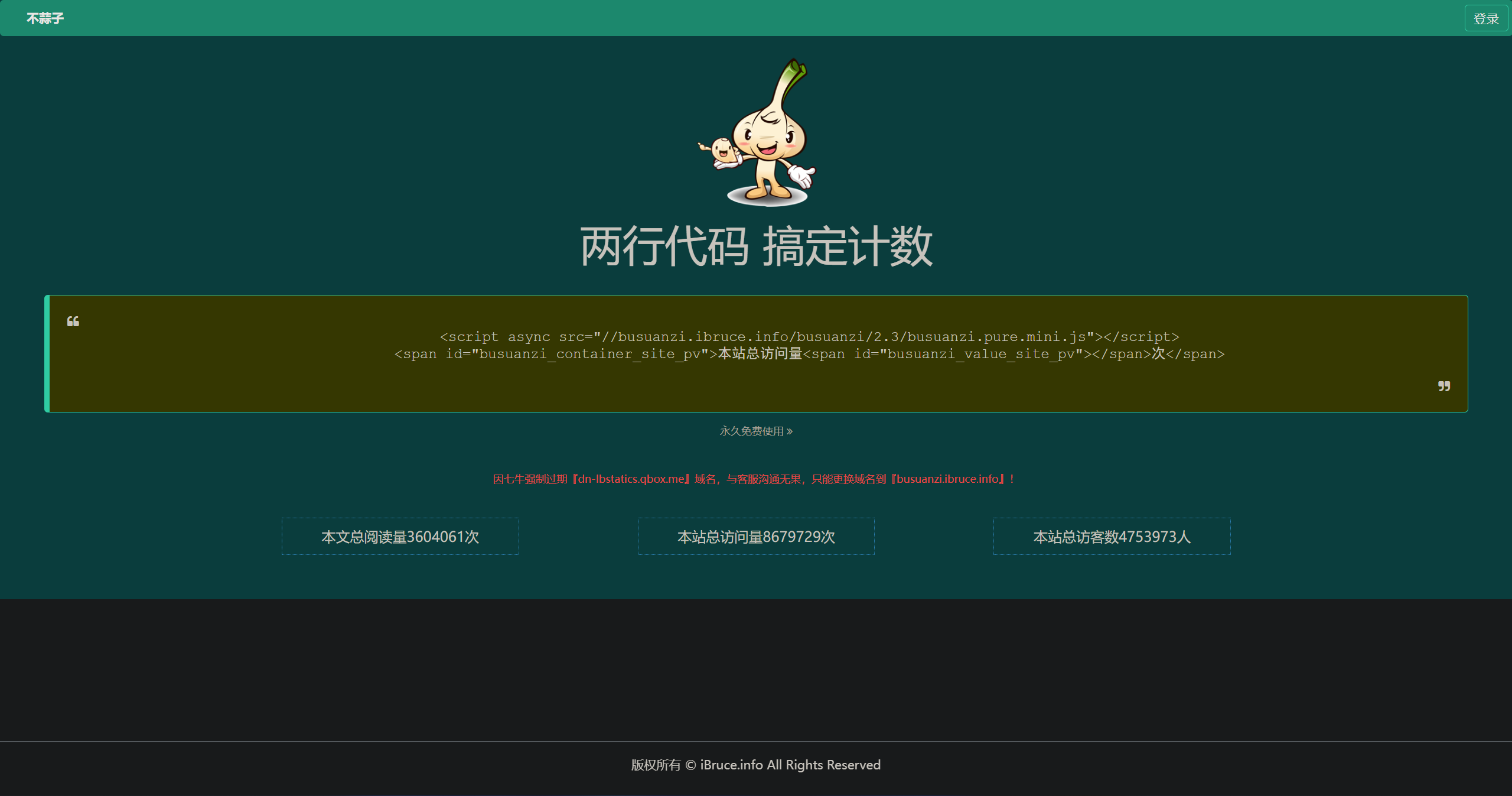
你可以按照官方的教程走,我是这么写的:
<script async src="//busuanzi.ibruce.info/busuanzi/2.3/busuanzi.pure.mini.js"></script>
<div>
<span id="busuanzi_container_site_pv" style="display: inline-block;">
👁️本站总访问量: <span id="busuanzi_value_site_pv" class="white-color"></span> 次
</span>
<span id="busuanzi_container_site_uv" style="display: inline-block;">
| <img src="/wp-content/uploads/2023/10/58e8ff52eb97430e819064cf.png" alt="User Icon" style="width: 1em; height: 1em; vertical-align: middle;"> 总访问人数: <span id="busuanzi_value_site_uv" class="white-color"></span> 人
</span>
</div>这样就会生成如图所示的效果,这里的

现在就是调整访问次数了,虽然不蒜子提供了一个方法运行我们初始化一开始的访问数量,但是假如我们想有计划的伪造数据,比如慢慢增长,让网站的访问量慢慢上升,营造一种蒸蒸日上的氛围,又改怎么办呢?
想要改变网站访问次数,我们就要知道不蒜子是怎么工作的,我第一时间想到的是Referer,猜测不蒜子服务器在发送之前讲到的那个js文件的同时根据referer判断访问来源,同时计算网站访问次数
F12+F5查看和不蒜子有关的流量,找到了js的请求URL,重新发包,却发现访问次数并没有增加,这是为什么呢?
我再次查看了js,发现这个js只是实现了另一个网络请求,之前还是太草率了
重新查看流量,找到了真正统计用的请求
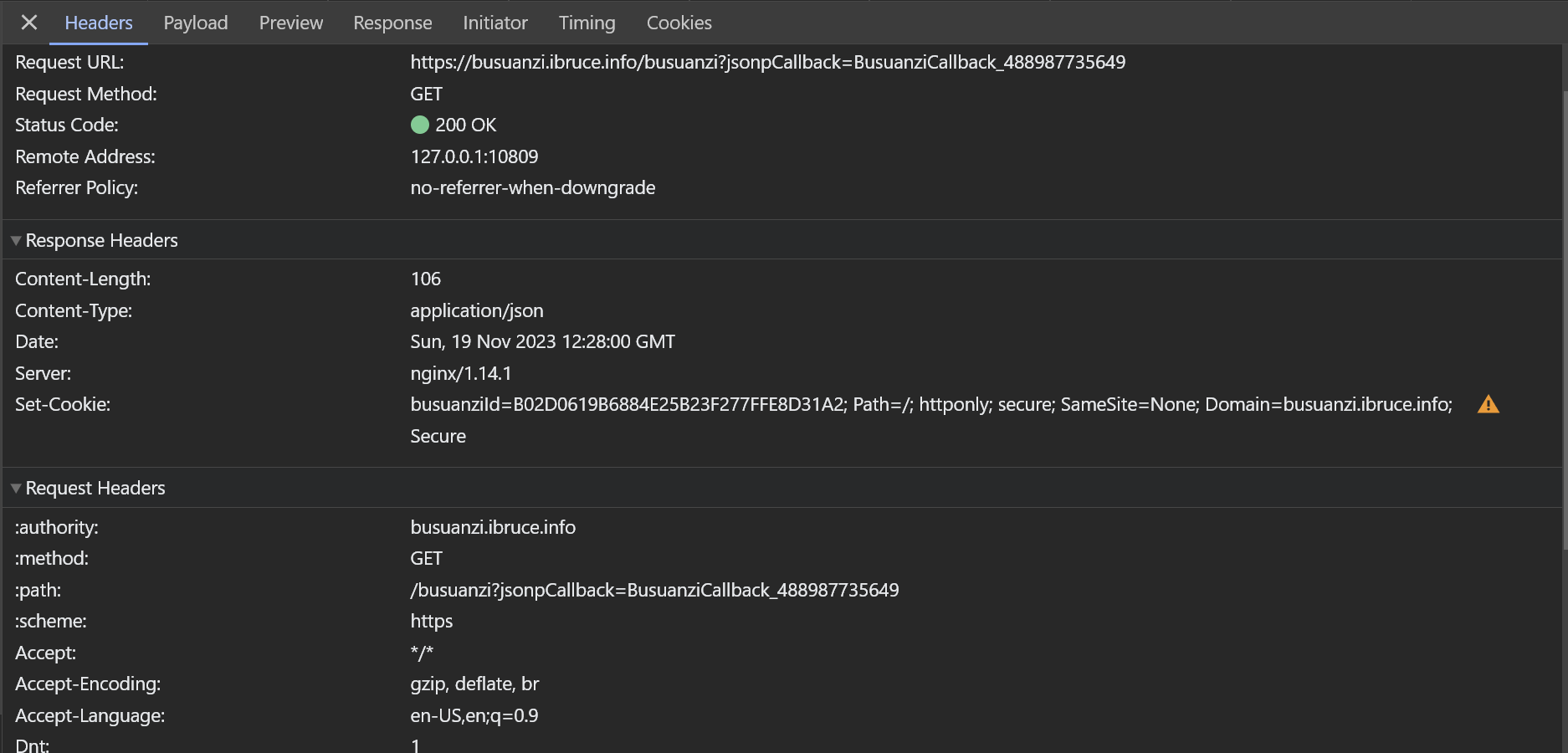
可以看出,这里主要的参数有jsonCallback,busuanziid,当然还有Referer(截图里没有体现)
我们猜测这里的Cookie里的busuanziid是用来标识网站访客的,这里由于我的浏览器自动清除了第三方网站cookie导致我每次刷新都相当于新访客的访问…

猜测这里的site_uv是网站访问量,page_pv是单个页面访问量,version不重要然后site_pv是访客数
理论可行,接下来实战
掏出祖传py,编写以下代码
import requests
headers={'Referer':'https://your_site's_url/'}#把这里改为你的URL
while True:
requests.get('https://busuanzi.ibruce.info/busuanzi?jsonpCallback=BusuanziCallback_780656139386',headers=headers)
#这里的BusuanziCallback_780656139386
是我自己请求直接复制下来的,可能是之前那个js代码生成的,如果不放心可以模拟请求然后复制即可这样你的py就会不停的帮你开刷,这是我刷了不到一天的结果(中间由于不可抗因素断过几次)

细心的朋友可能已经发现了,之前这种不携带Cookie的请求会导致每一次访问都会同时增加访问量和访客数,所以当时我一开始没有带Cookie,刷到下午一点时是这样的:
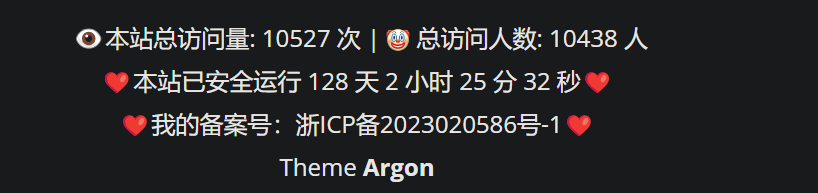
显然不太真实啊这数据 虽然这几w的访问量更不真实
只要携带同一个Cookie一直访问即可只提高访问量(,Cookie可以通过模拟请求获得,或者你使用requests的Session模块来处理Cookies
再来说说效率问题,我觉得几w的访问量已经很逆天了,有之前的图片为证:
但是如果你觉得刷一天太麻烦,或许你可以考虑多线程,multiprocessing pool之类的(我不是Dev✌我不会),或者你可以部署在你的vps上就可以一直运行,或者像我这样既不会多线程又在之前提前把pip玩坏的人可以考虑另一种办法:
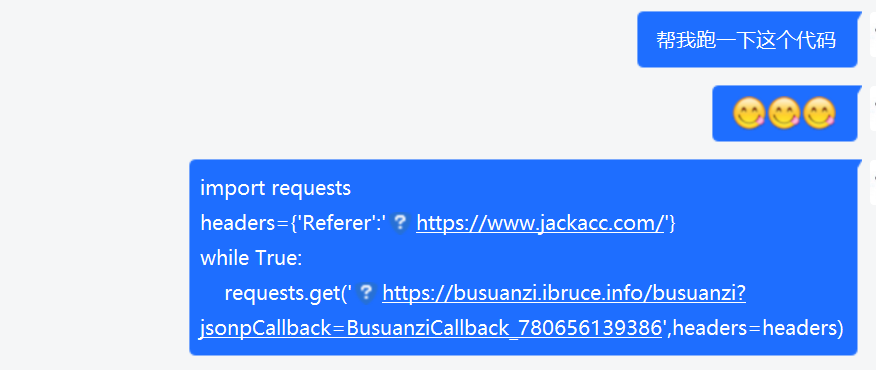
但这么做其实还是有破绽
一个几万访问量的网站,里面文章的访问量却是这样的:

而且我估计Wordpress的访问系统和不蒜子的访问计数是分离的,说到底了,还是要去爬网站文章本身,而爬网站网页和爬单独的一个json数据,耗时完全不在一个数量级
完结撒花

import requests
headers={‘Referer’:’https://www.jackacc.com/‘}
while True:
a=requests.get(‘https://busuanzi.ibruce.info/busuanzi?jsonpCallback=BusuanziCallback_780656139386‘,headers=headers)
print(a.text)
这几个月居然有800的访问量….不敢相信